Scaling Optical Transformers to Causal Language Models#
Following the Optical Neural Networks on RoBERTa experiments, we scale the Optical Transformer to causal language models (CLMs). This tutorial demonstrates full fine-tuning of a pretrained CLM with Mase-triton acceleration.
Note
If you have not set up the environment yet, follow Installation first.
Starting Points Explored#
We evaluated three starting points before settling on the main approach:
Full Fine-Tuning with Optical Transformer#
Entry point: experiments/llm-optical-transformer/continual_finetuning/run_clm_no_trainer.py
Optical Transformer configuration#
The optical transformer is configured through a TOML file (experiments/llm-optical-transformer/continual_finetuning/transform_cfg.toml):
use_lora— set tofalsefor full fine-tuningattention.q_levels— quantization levels (default: 256)attention.q_lut_min— minimum LUT value (default: 0.020040)attention.q_smooth_factor— smoothing factor for running statistics (default: 0.9)attention.q_init_seed— random seed (default: 0)attention.q_bypass— bypass quantization in attention layers (default: false)fc— same parameters apply to fully-connected layers
Training setup#
Setting |
Value |
|---|---|
Pretrained model |
|
Dataset |
|
Fine-tuning tokens |
|
Learning rate |
Sweep from 1e-7 to 1e-5 depending on model size. Larger models require smaller rates. |
Effective batch size |
16 (via gradient accumulation steps and number of processes) |
Basic fine-tuning command#
Run from the repository root:
cd experiments/llm-optical-transformer/continual_finetuning
MODEL_NAME="AICrossSim/clm-60m"
DATASET_NAME="Cheng98/fineweb-edu-1.25B"
OUTPUT_DIR="./output/clm-60m-optical"
TRANSFORM_CFG="./transform_cfg.toml"
accelerate launch --num_processes=1 \
run_clm_no_trainer.py \
--model_name_or_path "${MODEL_NAME}" \
--dataset_name "${DATASET_NAME}" \
--per_device_train_batch_size 8 \
--learning_rate 2e-5 \
--weight_decay 0.01 \
--num_train_epochs 1 \
--gradient_accumulation_steps 2 \
--lr_scheduler_type linear \
--output_dir "${OUTPUT_DIR}" \
--preprocessing_num_workers 32 \
--trust_remote_code \
--with_tracking \
--report_to wandb \
--transform_cfg "${TRANSFORM_CFG}" \
--block_size 1024 \
--log_train_loss_steps 50
Warning
Learning rate is critical. Optical Transformer fine-tuning requires a very small learning rate (< 1e-5) for stable training. Larger learning rates cause loss divergence. The larger the model, the smaller the required learning rate.
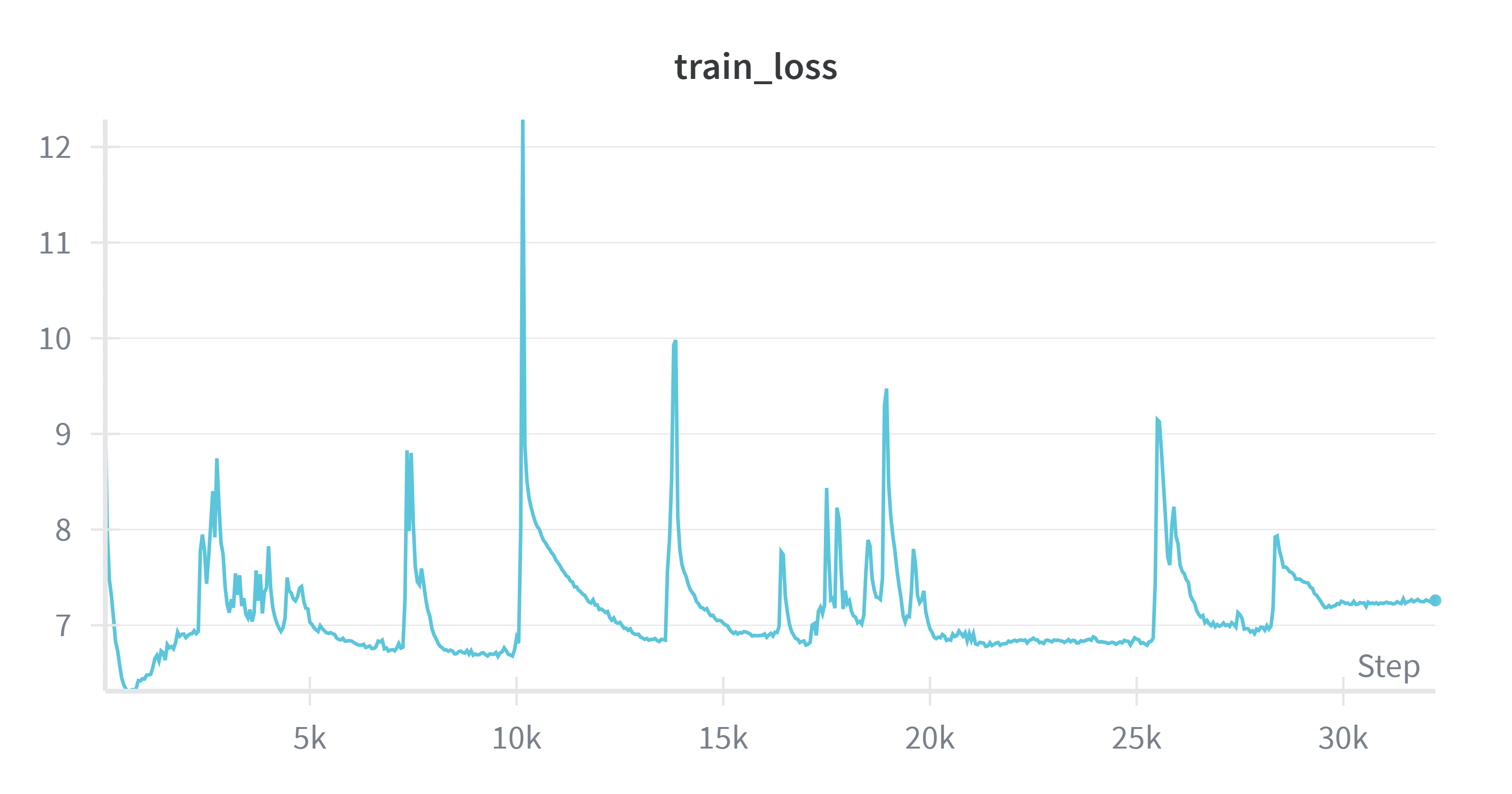
CLM-400M with learning rate too high — loss diverges.#
Using the shell script#
fine-tune-ot-clm.sh automatically calculates training steps and configures W&B logging:
cd experiments/llm-optical-transformer/continual_finetuning
# Default parameters
./fine-tune-ot-clm.sh
# Custom parameters
# Usage: ./fine-tune-ot-clm.sh [num_processes] [model_name_or_path]
# [per_device_train_batch_size] [learning_rate] [weight_decay]
# [gradient_accumulation_steps] [block_size]
./fine-tune-ot-clm.sh 2 "AICrossSim/clm-200m" 4 "1e-5" 0.01 4 1024
Learning rate sweep#
cd experiments/llm-optical-transformer/continual_finetuning
# Edit sweep.sh to set desired learning rate ranges, then run:
./sweep.sh
Results#
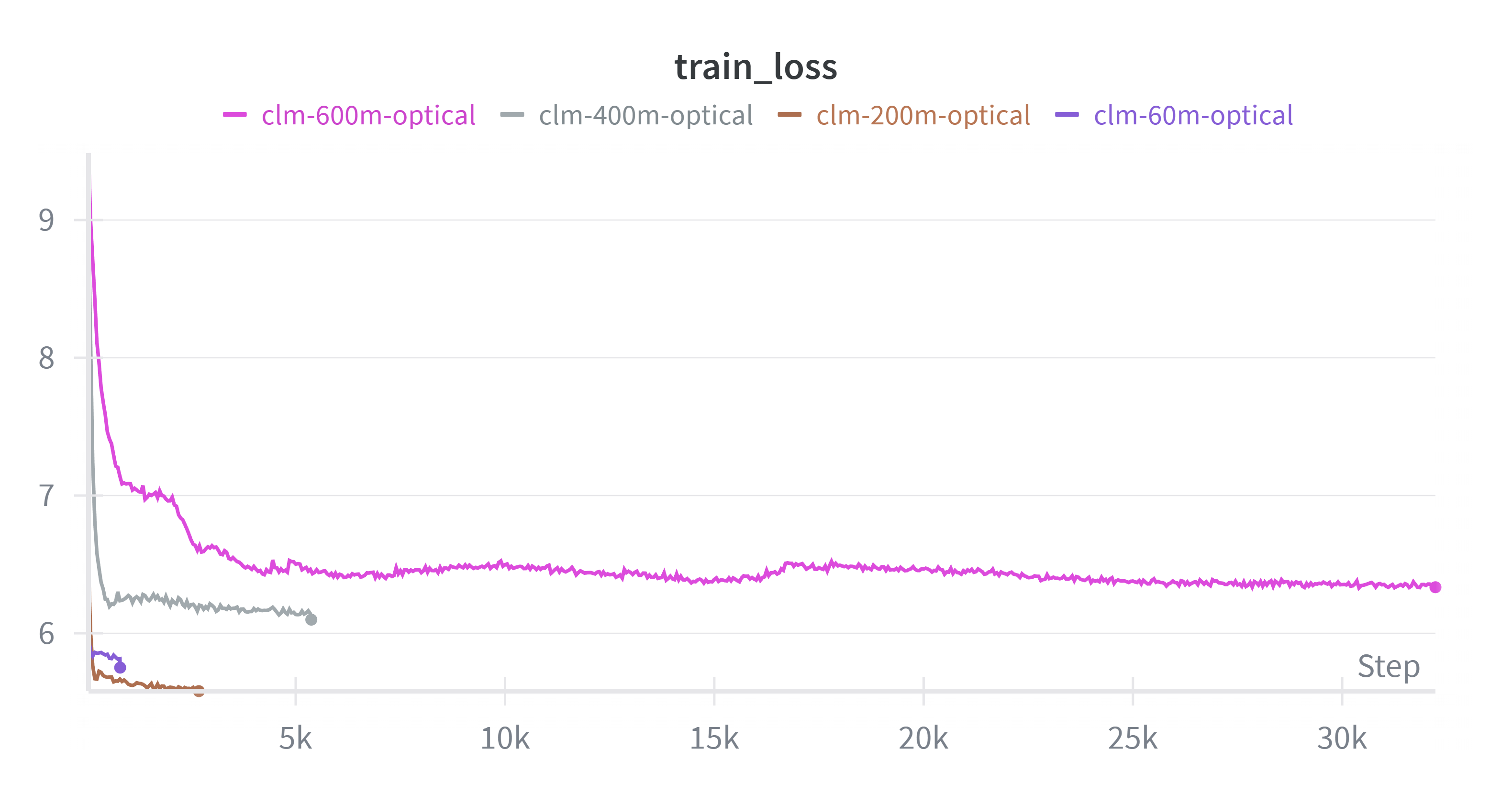
Training loss for full fine-tuning across CLM model sizes (traces smoothed for clarity).#
More traces with various learning rates: W&B Project: OT-CLM-full-ft
Takeaway: Full fine-tuning of pretrained optical CLM models does not scale as well as standard CLM fine-tuning. We observe moderate improvement for smaller models (60M → 200M), while larger models (400M, 600M) show degraded performance.